
Three AIs each put together a real 100-part machine in design software, on their own. None got it perfect. But they did it without help, and they should improve quickly.
AI can write and draw. But can it build a real machine — one made of metal parts that have to fit together? We decided to test it.
The short answer: yes, it can build one. Not yet well enough to build from. But it did it on its own, which is a real step.

What we did
We gave three different AIs the same job: here is a box of parts — the aluminum rails, plates, wheels, and motors you’d use to build a big 3D printer — and here is a picture of the finished machine. Now put it together.

Two of the AIs were Claude (from Anthropic). The third was OpenAI’s Codex — its coding helper, not the chat app you might know.
We did not tell them the steps. We didn’t say “start here, then do this.” We let each AI figure out how to reach the machine in the picture. That tests something real: does the AI actually understand how the parts go together?
What happened
All three placed every part, about 100 of them, with no human help. That is the good news.
The honest news: none of them got it fully right. In every build, some parts overlapped — two pieces of metal trying to sit in the same spot — and the corner posts were turned the wrong way. So you couldn’t actually build these machines yet.
Even so, the basic result is notable. From one picture and a box of parts, with no instructions, a whole machine took shape on its own. One AI did it in 13 minutes, on its first try, with no do-overs. Getting every part to fit exactly is the next step, and now we can measure it.
How do we know?
We built an automatic checker. You hand it the finished design and, in seconds, it asks the questions a careful engineer would: Are all the parts there? Do any parts overlap? Is anything floating loose, attached to nothing? Then it gives the try a score.
Different models led different dimensions. Claude · CadQuery hit the answer key’s interface gaps almost exactly — 0 mm median error — but took 49 minutes. OpenAI Codex one‑shot it in 13 minutes with the loosest gaps but the most rotations correct (69%). Tolerances are tight by design (≤5 mm to count as “located”) because real equipment runs on fractions of a millimetre.
MARB v0.9 GAP median: CadQuery 0.0 mm · Fusion 2.0 mm · Codex 7.8 mm | ORIENT aligned: Codex 69% · CadQuery 51% · Fusion 47% | target = 0 mm gap, 100% aligned
There was also a clear trade‑off. OpenAI’s Codex was fast — 13 minutes, one shot — with the loosest gaps but the most rotations right. A Claude · CadQuery run was slower (about 50 minutes) but checked its own work and hit the gap target exactly. Go fast, or go careful. The MARB metrics show both.
One honest note: our checker was first built around one of the design tools (called CadQuery), before the newer tool connection existed. So the builds that used that tool may have had a small head start. We say so on purpose — a fair test stays honest.

Why this matters
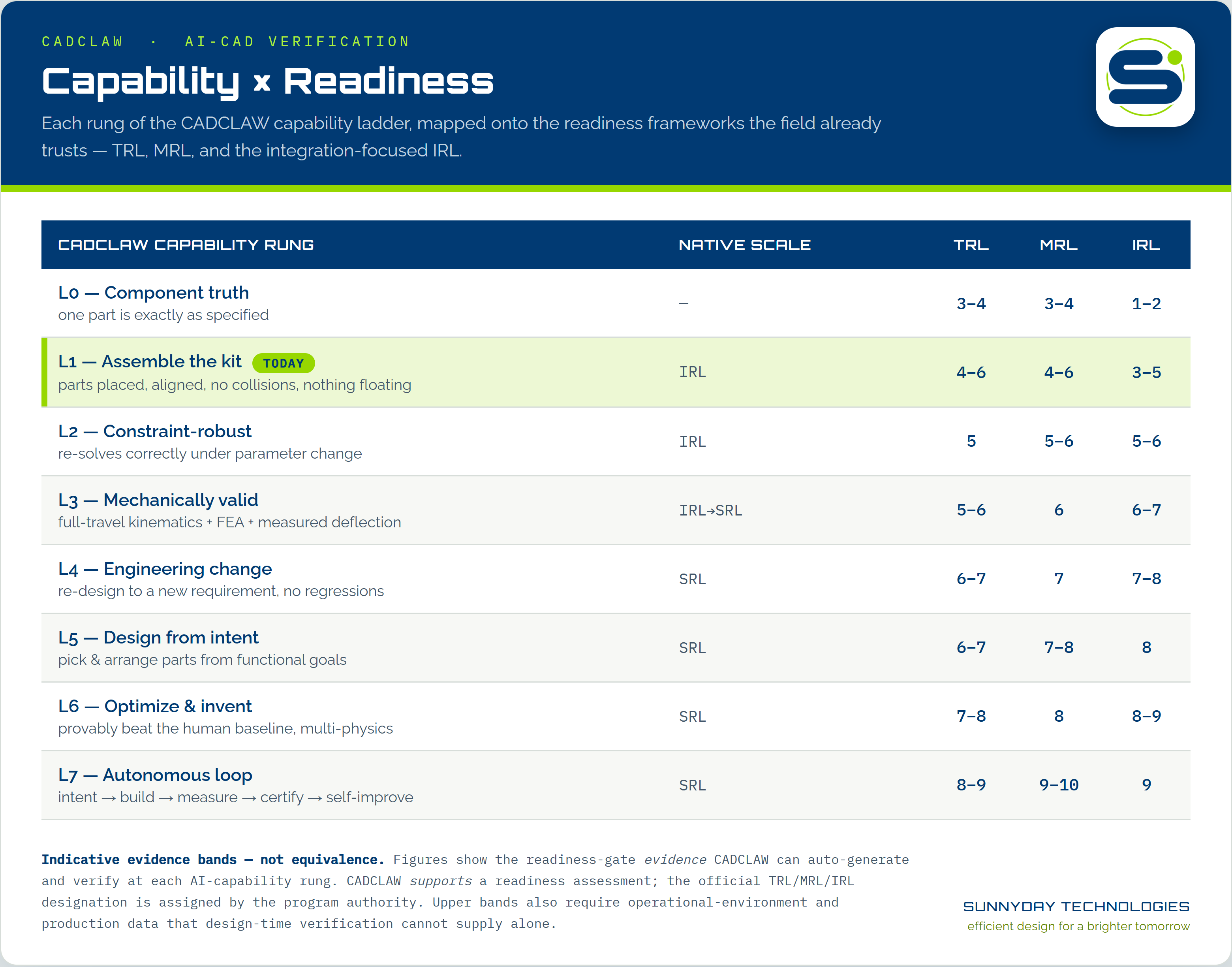
Until recently, there was no way to measure this. You need two things: an AI that can drive design software, and an automatic checker that says whether the result is right. They only recently became usable together.
With both in place, every attempt gets a score. A clear scoreboard tends to speed a field up, so we expect these scores to rise.
We call the scoreboard the Mechanical Assembly Readiness Benchmark. It works with any AI and any design tool, so the race stays fair. Today’s low scores are the starting line — not the finish.
The takeaway
A year ago, an AI building a real machine on its own was not something you could test. Now it is. The results are early and rough, but real. The point is not that it is perfect. The point is that it works at all, and that we can now measure how quickly it improves.
See the full results and method at cadclaw.io/benchmark. Sunnyday Technologies — efficient design for a brighter tomorrow.
Scores shown are Sunnyday Technologies’ own measurements from a published method, on the software versions and dates shown — each a single run of one task, not a statement about any product’s overall quality, performance, or fitness for any purpose. Provided “as is,” for informational purposes, without warranty. Sunnyday Technologies is independent and is not affiliated with, sponsored by, or endorsed by Anthropic, OpenAI, or Autodesk. M3-CRETE™ and CEMFORGE™ are trademarks of Sunnyday Technologies; Claude, OpenAI Codex, Autodesk Fusion, and CadQuery are trademarks of their respective owners, used here only to identify the tools tested.